






多任务执行方式
前言
所有的代码,以兼容性考虑,会优先使用C++语言支持的函数。
程序的执行,从本质上来说,需要落到具体的物理核心的基础运算中。也就是我们常说的处理器物理核心,单核的处理器,永远也不可能使用真正意义上的并行计算。而是通过一些数据手段,加上处理器的高频,模拟出多任务并行的表象。
但是,几乎所有的有价值的业务,都需要处理大量的数据,而复杂系统难以被拆分为线性的运算。加之处理器核数的增加,使用单一核心显然不符合最佳的优化方案。于是,并行计算就被提上了日程。
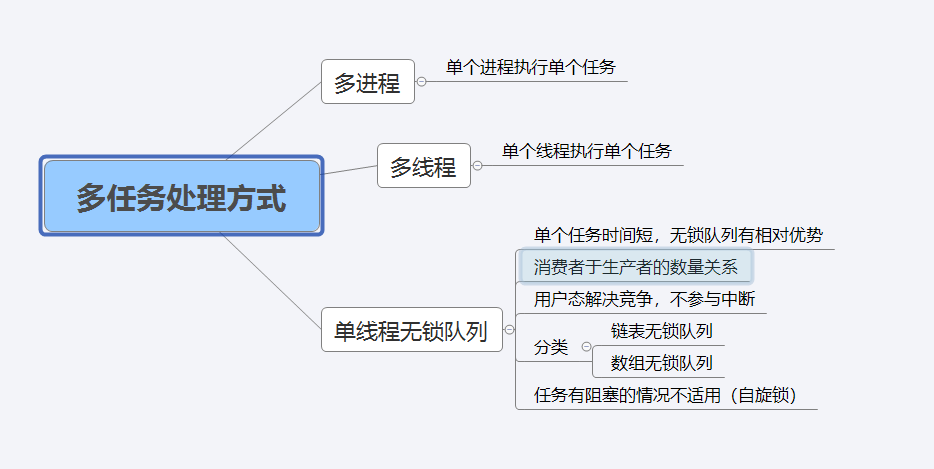
现有的并行计算无外乎两个方向:拆解任务、提升处理核心数量;或是保护资源,切换执行顺序。
前者代表硬件的提升,而后者代表软件的优化。
多任务执行的思路
前文中我们已经提及过,目前的多任务处理机制主要分为两个部分。提升核心数量意味着资源分配的提升,属于很快就能触及金钱边界的方式;而锁止资源,切换执行顺序则需要一个较为严谨的锁制逻辑,并且严格约束执行顺序的切换。由于第二种方式的成本相对可控,同时大部分的应用场景对于纳秒级别的延迟并不在意,这也是我们软件人员的工作重点。(注意,我们锁称的锁包含了自旋锁,严格来讲所有的等待都是一种广义的锁)
多进程执行多任务
进程是系统分配资源的最小单位,线程是程序执行的最小单位。倘若我们希望使用更多的核心进行多任务处理,在当前的操作系统中就不得不创建更多的进程来进行计算。
换计划说,多进程可能是最简单粗暴的任务解决方案。
要想实现多进程,我们可以使用fork这个系统函数调用。该函数是linux下的一个系统调用,fork()通过复制一个现有进程来创建一个全新的进程。即相当于使用了clone()。系统会将父进程的部分数据(数据、堆、栈)进行复制,至于共享库等,在linux下本身就是只有一份的,所以共享持有。
#else if __linux__
pid_t pid = fork();
if (pid == -1)
{
//perror("fork");
exit(-1);
}
但是,在windows下,是没有这个函数的。需要使用createprocess这个函数。熟悉系统的同学可能发现了,windows下的PE结构虽然与linux的elf相差无几,但是其对共享资源的处理却是不同的,在windows下,我们难以像linux一样简单的调用系统函数复制创建进程。进程之间的独立性更强。
然后我们回过头看这个CreateProcess,它需要我们明确的调用一个可执行文件,用于创建新的进程。也就是说,和我们从主程序中点击exe几乎相同。当然,在cfgwin等三方库中有在windows下对于fork函数的模拟。
#ifdef _WIN32
STARTUPINFO si;
PROCESS_INFORMATION pi;
ZeroMemory(&si, sizeof(si));
si.cb = sizeof(si);
ZeroMemory(&pi, sizeof(pi));
LPCWSTR start_exe(L"C:\\Bolg\\article\\多任务的分配与执行\\hello.exe");
// Start the child process.
if (!CreateProcess(start_exe, // No module name (use command line)
NULL, // Command line
NULL, // Process handle not inheritable
NULL, // Thread handle not inheritable
FALSE, // Set handle inheritance to FALSE
0, // No creation flags
NULL, // Use parent's environment block
NULL, // Use parent's starting directory
&si, // Pointer to STARTUPINFO structure
&pi) // Pointer to PROCESS_INFORMATION structure
)
{
printf("CreateProcess failed (%d).\n", GetLastError());
return;
}
多线程执行
多线程是相当常见的多任务处理方式,也是相关概念最多的部分。
线程是程序执行的单位,它不拥有独立的资源,无法隔离其他线程的访问权限;但是它有独立的执行逻辑,可以获取或者失去执行权限。
因为线程并行执行的原理是挂起未获取“通行证”的其他线程,从而实现多个线程“并行”的执行效果,所以,在代码中多线程有很多的实现方式,有多种结构可以充当这张“通行证”,互斥量、锁、临界区等结构都可以完成这个工作。
当线程失去“通行证”之后,会发生什么呢?首先我们需要陷入内核态,操作系统暂时接管执行权限,是保存当前执行现场(栈信息,上下文信息),方便之后继续执行下去。接着会将执行环境切换到有通行证的线程中,最后退出内核态,完成程序的线程切换。
在具体的代码实现中,我们可以选择不同系统提供的线程函数,也可以使用一些跨平台的工具或者使用语言本身的标准。我们这里使用C++ 11之后新增的线程库。
我们给出一种参考的实现方式
#define MAX_THREADNUM 32
using FunC_V = std::function<void()>;
using FunC_B= std::function<bool()>;
using Task = FunC_V;
class multi_thread final
{
public:
static multi_thread* getInstance();
virtual ~multi_thread();
bool addThread(int inum);
template <typename fuc,typename ...Arg>
auto commitTask(fuc&& f, Arg&& ...args)->std::future<decltype(f(args...))>
{
if (!_run) throw std::runtime_error("");
using RetType = decltype(f(args...));//收集返回的类型值,匹配出一个函数来
auto task = std::make_shared<std::packaged_task<RetType()>>(//打包异步任务
std::bind(std::forward<fuc>(f), std::forward<Arg>(args)...)
);
std::future <RetType>future = task->get_future();//定义异步任务返回
{
std::lock_guard<std::mutex>lock{ _lock };
_que_task.emplace([task]() {(*task)(); });
}
_cond_task.notify_one();
return future;
}
std::atomic<bool> _run{ true };
private:
multi_thread()=delete;
multi_thread(int inum);
multi_thread(const multi_thread&) = delete;
multi_thread operator()() = delete;
static multi_thread* _pth;
static std::once_flag once_fg;
std::vector<std::thread> _vec_pool;
std::queue<Task> _que_task;
volatile std::atomic<int> _idle_num = 0;
volatile std::atomic<int> _max_num = 0;
std::mutex _lock;
std::condition_variable _cond_task;
};
#include "multi_thread.h"
multi_thread* multi_thread::_pth=nullptr;
std::once_flag multi_thread::once_fg;
using namespace std;
multi_thread* multi_thread::getInstance()
{
std::call_once(once_fg,[]() {
_pth=new multi_thread(0);
});
return _pth;
}
multi_thread::multi_thread(int inum)
{
if (inum < 0)return;
_pth = this;
int maxnum = (inum < MAX_THREADNUM) ? inum:MAX_THREADNUM;
addThread(inum);
}
multi_thread::~multi_thread()
{
_run = false;
_cond_task.notify_all();//唤醒所有任务
for (auto & thread : _vec_pool)
{
if (thread.joinable())
{
thread.join();
}
}
}
bool multi_thread::addThread(int inum)
{
auto add_thread = [this]{
Task task;
{
unique_lock<mutex>lock{ _lock };
auto pre_lock = [this]()->bool {return(_run || !_que_task.empty()); };
_cond_task.wait(lock, pre_lock);//前置条件:任务队列不为空且线程池工作(此处不阻塞)
if (!_run)return;
if (_que_task.empty())return;
task = move(_que_task.front());
_que_task.pop();
}
_idle_num--;
task();
_idle_num++;
};
while (inum--)
{
_vec_pool.emplace_back(add_thread);
_idle_num++;
}
return true;
}
无锁队列
上文中描述的多线程在大部分环境下已经足够优秀,但是无法避免的是它需要操作系统内核态的参与。线程的切换在一定程度上是感知不强的,但是如果程序中频繁的触发线程的切换,还是会导致宝贵的CPU资源被用于“无用”的程序中。所以,我们希望在用户态就解决这个问题,达到和线程相近的功能。
注意,所谓的更高效的无锁队列并不是在所有情况下都适用,除开读写的经典场景,在计算、网络等场景下,都不建议使用无锁队列。
而所谓的无锁队列,在实际的使用中并没有摆脱线程,甚至也不是“无锁”的,它往往和线程、互斥量等配合使用,用“用户态并行数据结构”去形容他会更准确一点。
首先,我们需要明确其使用环境,我们常见的程序并行结构解决的都是生产者+消费者的场景。
既然是并行结构,就需要考虑多个生产者+多个消费者的情况。(其他情况我们跳过)
我们可以想象有一个资源池子,生产者不断地生产资源丢进这个池子里面,消费者不断地从这个池子中获取资源进行消费。发现了吗,这里的生产者和消费者完全可以是多线程或者多进程的,我们并没有限定其关系。
这个池子,在某种意义上来说就是我们的无锁队列,也是装载资源的容器。至此,我们都没有谈到它到底在哪里“无锁”了,答案就是在操作资源的时候,每当我们想在池子里捞或者抛出资源,都需要使用这个池子提供的方法。从某种意义上来说,这也是类并行的一种,我们需要提供一个方式,可以有条不紊的管理资源。
首先,我们需要一个资源的最小单位容器,这里我们使用链表的形式(资源获取时不提供查询),同时,我们需要提供一个高效获取和插入资源的方法。为了将获取、插入都整理为线性的执行,我们需要引入CAS的概念。
CAS可以理解为compare & swap,它将对比期望值和当前值,并且重新检查设定当前值,在C++中函数为atomic_compare_exchange_strong(也有weak);
从函数名就可以看出,这是一个原子操作,它的解释如下:
_Bool atomic_compare_exchange_strong(volatile A * obj,C * expected,C desired);
当前值与期望值(expect)相等时,修改当前值为设定值(desired),返回true
当前值与期望值(expect)不等时,将期望值(expect)修改为当前值,返回false
这个操作的目的是为了确保在交换的时候(push或者pop),当前交换的值是我们期望的,没有被其他线程干扰。
下面是我们借鉴他人实现简单的搭建了的队列,注意,此代码的性能瓶颈很低,仅做参考使用。
#pragma once
#include <atomic>
#include <queue>
#include <memory>
#include <iostream>
template<typename T>
struct Node {
using SPtr = std::shared_ptr<Node>;
T _val;
SPtr _next = nullptr;
};
template<typename T>
class NoLockQueue final {
private:
mutable std::atomic_int32_t _size=0;
mutable std::atomic_bool _stop_push= false;
mutable std::atomic_bool _stop_pop= false;
std::shared_ptr<Node<T>> _front;
std::shared_ptr<Node<T>> _tail;
public:
NoLockQueue()
{
_front = std::make_shared<Node<T>>();
_tail = _front;
}
virtual ~NoLockQueue()
{
}
bool push(const T& val) {
if (_stop_push) return false;
typename Node<T>::SPtr last = nullptr;
typename Node<T>::SPtr new_node = std::make_shared<Node<T>>();
new_node->_val = val;
last = atomic_load(&_tail);
//CAS compare and swap
// 对比期望值和真实值是否相等
// 若期望值和真实值不相等返回false,将期望值设置为真实值
// 若期望值和真实值相等交换期望值和设定值返回true
//1.判断真实_tail是否等于期望last 等于:交换成功_tail == new_node,
//2. 不等于:last = 真实_tail,继续尝试交换
while (!std::atomic_compare_exchange_strong(&_tail, &last, new_node));
//3.交换成功 _tail = new_node
//4.last->next = new_node;
std::atomic_store(&(last->_next), new_node); //
++_size;
return true;
}
bool push(T&& val) {
if (_stop_push) return false;
typename Node<T>::SPtr last = nullptr;
typename Node<T>::SPtr new_node = std::make_shared<Node<T>>();
new_node->_val = std::move(val);
last = atomic_load(&_tail);
//CAS compare and swap
// 对比期望值和真实值是否相等
// 若期望值和真实值不相等返回false,将期望值设置为真实值
// 若期望值和真实值相等交换期望值和设定值返回true
while (!std::atomic_compare_exchange_strong(&_tail, &last, new_node));
std::atomic_load(&(last->_next), new_node);
++_size;
return true;
}
bool pop(T& val) {
if (_stop_pop) return false;
typename Node<T>::SPtr first = nullptr;
typename Node<T>::SPtr first_next = nullptr;
do {
first = std::atomic_load(&_front);
first_next = std::atomic_load(&(_front->_next));
if (!first_next) return false;
//CAS compare and swap
// 对比期望值和真实值是否相等
// 若期望值和真实值不相等返回false,将期望值设置为真实值
// 若期望值和真实值相等交换期望值和设定值返回true
} while (!std::atomic_compare_exchange_strong(&_front, &first, first_next));
--_size;
val = std::move(first_next->_val);
return true;
}
void show() {
for (auto it = _front; it != nullptr; it = it->_next) {
std::cout << it->_val << " ";
}
std::cout << std::endl;
}
int size() {
return _size;
}
bool empty() {
return _size == 0;
}
};
Q.E.D.

