







前言
遥想当年第一次学习C语言的时候,看着大佬把数组炫的飞起,我当时一阵头晕目眩,这不是编程,这TM是密码学……
于是我十分佩服程序员们的工作,能在这样原始的数据上编程,后来,我发现,车之所以能跑,是因为很早就有人发明了轮子。
所谓轮子,就是前人留下来的库函数,而在奇形怪状的库中,总有一些简洁而优雅的库,会被写进标准里。
它就叫…………标准库!
好了,话不多说。今天我们来介绍c++的标准库STL。
其实在C++开发人员的修仙路途中,STL仅仅是一个不起眼的小水坑,但是和其他高大上的技术比起来,它却是所有码农离不开的,下地干活的锄头。
当然,相比一些脚本语言,这把锄头可能比金箍棒还要大……
这篇文章,我们主要以《STL源码解析》一书中提出的框架与分类,进行STL的简单分享。
图片资源来自于网络,如有侵权请联系我删除。
分类
STL(Standard Template Library,标准模板库),是惠普实验室开发的一系列软件的统称。我们之后提到的部分可以简单理解为C++自带的标准函数库。
STL 从广义上分为: 容器(container) 算法(algorithm) 迭代器(iterator),容器和算法之间通过迭代器进行无缝连接。
容器:各种数据结构,如vector、list、deque、set、map等,用来存放数据,从实现角度来看,STL容器是一种class template
算法:各种常用的算法,如sort、find、copy、for_each。从实现的角度来看,STL算法是一种function tempalte.
迭代器:扮演了容器与算法之间的胶合剂,共有五种类型,简单来说就是对于前进后退等操作的重载实现。原生指针(native pointer)也是一种迭代器。
仿函数:行为类似函数,可作为算法的某种策略。从实现角度来看,仿函数是一种重载了operator()的class 或者class template
空间配置器:负责空间的配置与管理。从实现角度看,配置器是一个实现了动态空间配置、空间管理、空间释放的class tempalte.
容器
容器是用来存放元素的一种特定的数据结构,根据数据在容器中的排列特性,这些数据分为序列式容器和关联式容器两种。
常见的容器包括:数组(array),链表(list),tree(树),栈(stack),队列(queue),集合(set),映射表(map),
序列式容器强调值的排序,序列式容器中的每个元素均有固定的位置,除非用删除或插入的操作改变这个位置。Vector容器、Deque容器、List容器等。
关联式容器是非线性的树结构。各元素之间没有严格的物理上的顺序关系,也就是说元素在容器中并没有保存元素置入容器时的逻辑顺序。关联式容器另一个显著特点是:在值中选择一个值作为关键字key,这个关键字对值起到索引的作用,方便查找。Set/multiset容器 Map/multimap容器
String

我们看一看一个string有什么属性和元素
// STRUCT TEMPLATE _Char_traits (FROM <string>)
template <class _Elem, class _Int_type>
struct _Char_traits { // properties of a string or stream element
using char_type = _Elem;
using int_type = _Int_type;
using pos_type = streampos;
using off_type = streamoff;
using state_type = _Mbstatet;
……}
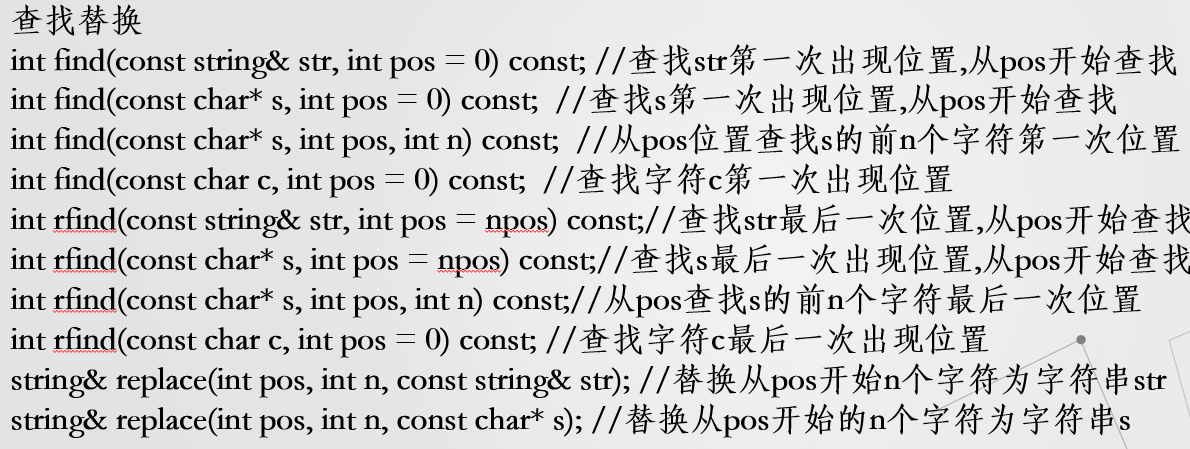
我们需要熟悉一下STL的编写风格,用简单的两张截图为例

简单的解释:
1.#define _CONSTEXPR20 inline
2.Out_writes_all_与_In_reads:写入与读出
3.Noexcept(1/0):被修饰的函数不会(会)发生异常
4.__cpp_lib_is_constant_evaluated:检查函数调用是否出现在常量求值的场合。若对调用的求值出现在明显常量求值的表达式或类型转换的求值中,返回 true ,否则返回 false 。


一些小问题:
1.At 与[]有什么区别?
答案:At是抛异常;[]直接崩溃
2.如果你来优化memcpy,该怎么优化?
参考:
https://www.zhihu.com/question/35172305
https://lore.kernel.org/lkml/tip-59daa706fbec745684702741b9f5373142dd9fdc@git.kernel.org/
Vector
Array是静态空间,一旦配置了就不能改变,要换大一点或者小一点的空间,可以,一切琐碎得由自己来,首先配置一块新的空间,然后将旧空间的数据搬往新空间,再释放原来的空间。Vector是动态空间,随着元素的加入,它的内部机制会自动扩充空间以容纳新元素。
Vector的实现技术,关键在于其对大小的控制以及重新配置时的数据移动效率,一旦vector旧空间满了,如果客户每新增一个元素,vector内部只是扩充一个元素的空间,实为不智,因为所谓的扩充空间(不论多大),一如刚所说,是”配置新空间-数据移动-释放旧空间”的大工程,时间成本很高,应该加入某种未雨绸缪的考虑,稍后我们便可以看到vector的空间配置策略。
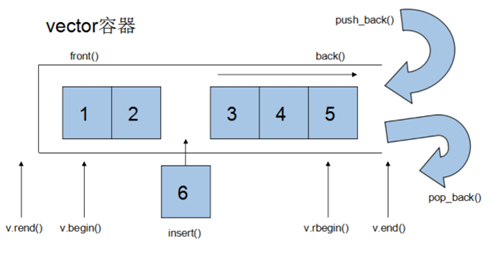
Vector的内存申请机制是一个vector的招牌特征。
不同的编译器、不同的库、不同的系统,给你的答案是不一致的。
但是,我们仍然可以总结它的申请方式,那就是当申请的内存不够使用的时候,它会根据你的申请行为(每次申请大内存还是小内存)来扩大申请【这里不一定是2倍或者50%等所有你从课本上看来的值】,然后将数据进行整体的迁移。
同时,由于每次申请的内存并不是和之前的内存相邻的,所以我们在使用vector的时候需要时时关注迭代器的指向,不要使用已经失效的迭代器
同时,注意内存谁申请谁销毁的原则,如果你额外new了内存,并将其给vector管理,在vector不再管理之后,及时的进行销毁。



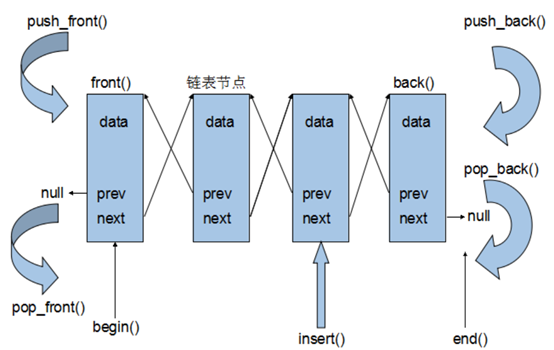
List
链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域
相较于vector的连续线性空间,list就显得负责许多,它的好处是每次插入或者删除一个元素,就是配置或者释放一个元素的空间。因此,list对于空间的运用有绝对的精准,一点也不浪费。而且,对于任何位置的元素插入或元素的移除,list永远是常数时间。
List容器是一个双向链表。
queue
Queue是一种先进先出(First In First Out,FIFO)的数据结构,它有两个出口,queue容器允许从一端新增元素,从另一端移除元素。

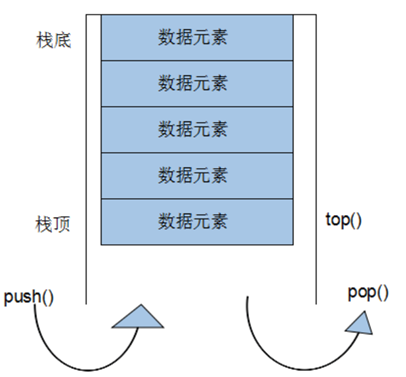
stack
stack是一种先进后出(First In Last Out,FILO)的数据结构,它只有一个出口,形式如图所示。stack容器允许新增元素,移除元素,取得栈顶元素,但是除了最顶端外,没有任何其他方法可以存取stack的其他元素。换言之,stack不允许有遍历行为。
有元素推入栈的操作称为:push,将元素推出stack的操作称为pop
set|multiset
Set的特性是。所有元素都会根据元素的键值自动被排序。Set的元素不像map那样可以同时拥有实值和键值,set的元素即是键值又是实值。Set不允许两个元素有相同的键值。
我们可以通过set的迭代器改变set元素的值吗?不行,因为set元素值就是其键值,关系到set元素的排序规则。如果任意改变set元素值,会严重破坏set组织。换句话说,set的iterator是一种const_iterator.
set拥有和list某些相同的性质,当对容器中的元素进行插入操作或者删除操作的时候,操作之前所有的迭代器,在操作完成之后依然有效,被删除的那个元素的迭代器必然是一个例外。
map|multimap
Map的特性是,所有元素都会根据元素的键值自动排序。Map所有的元素都是pair,同时拥有实值和键值,pair的第一元素被视为键值,第二元素被视为实值,map不允许两个元素有相同的键值。
我们可以通过map的迭代器改变map的键值吗?答案是不行,因为map的键值关系到map元素的排列规则,任意改变map键值将会严重破坏map组织。如果想要修改元素的实值,那么是可以的。
Map和list拥有相同的某些性质,当对它的容器元素进行新增操作或者删除操作时,操作之前的所有迭代器,在操作完成之后依然有效,当然被删除的那个元素的迭代器必然是个例外。
Multimap和map的操作类似,唯一区别multimap键值可重复。
Map和multimap都是以红黑树为底层实现机制。
hash|hashmap
什么是Hash :Hash 就是把任意长度的输入,通过哈希算法,变换成固定长度的输出(通常是整型),该输出就是哈希值。
这种转换是一种压缩映射(类似于一些校验的算法),也就是说,散列值的空间通常远小于输入的空间。不同的输入可能会散列成相同的输出,因此不能从散列值来唯一地确定输入值。简单的说,哈希就是一种将任意长度的消息压缩到某一固定长度的信息摘要函数。
通过引入哈希的概念,我们尝试组织一种查找(寻址)和改动(增删)都高效的一种数据结构
哈希表有多种不同的实现,其核心问题是如何解决冲突,即不同输入产生相同输出时,应该如何存储。
最经典的一种实现方法就是拉链法,它的数据结构是链表的数组(有时也叫bucket):
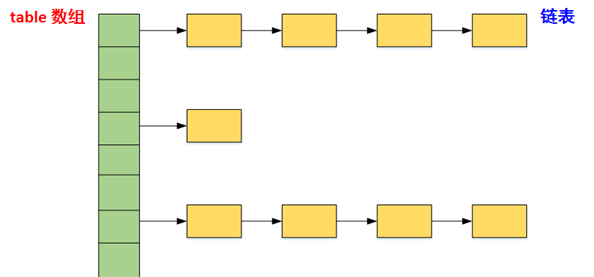
结构有了,接下来就是实现增删改查的事儿了。
首先,需要把数据存进去:
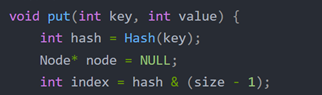
当我们拿到一个hashCode之后,需要将整型的hashCode转换成链表数组中的下标:
比如index作为下标:index = hashCode & (n-1);
但是位运算可能会带来index分布不均匀的问题,我们联想到取模运算的过程,取模的运算结果是几乎均匀的,我们可以得到等式:X % 2n = X & (2n – 1),所以问题就变成了如何让数组大小固定为2^n 。
size_t getTableSize(size_t capacity) {
// 计算超过 capacity 的最小 2^n
size_t ssize = 1;
while (ssize < capacity) {
ssize <<= 1; }
return ssize;}
接下来,我们就要把元素均匀地分配到各个桶内。
由于我们将使用key的hashCode来计算该元素在数组中的下标,所以我们希望hashCode是一个size_t类型。所以我们的哈希函数最首要的就是要把各种类型的key转换成size_t类型,可以用下面这种方法:
template<class KeyType>struct cache_hash_func {};
inline std::size_t cache_hash_string(const char* __s) {
unsigned long __h = 0;
for (; *__s; ++__s)
__h = 5 * __h + *__s;
return std::size_t(__h);}
template<>struct cache_hash_func<std::string> {
std::size_t operator()(const std::string & __s) const {
return cache_hash_string(__s.c_str()); }};
这样的方法生成的hash值仍然不够均匀,所以我们需要加入值的扰动机制,将高位和低位的特征结合起来:
size_t getHash(size_t h) const {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
算法
简介
算法,是对于解决问题方法的规则总结。以有限的步骤,根据输入解决逻辑或数学上的问题,给出确定的输出。
广义而言,我们所编写的每个程序都是一个算法,其中的每个函数也都是一个算法,毕竟它们都是用来解决或大或小的逻辑问题或数学问题。STL收录的算法经过了数学上的效能分析与证明,是极具复用价值的,包括常用的排序,查找等等。特定的算法往往搭配特定的数据结构,算法与数据结构相辅相成。
STL中的算法分为:质变算法和非质变算法。
质变算法:是指运算过程中会更改区间内的元素的内容。例如拷贝,替换,删除等等
非质变算法:是指运算过程中不会更改区间内的元素内容,例如查找、计数、遍历、寻找极值等等。
算法主要是由头文件
遍历|查找|排序
for_each(iterator beg, iterator end, _callback);
transform(iterator beg1, iterator end1, iterator beg2, _callbakc);
find(iterator beg, iterator end, value);
find_if(iterator beg, iterator end, _callback);
adjacent_find(iterator beg, iterator end, _callback);
binary_search(iterator beg, iterator end, value);
count(iterator beg, iterator end, value);
count_if(iterator beg, iterator end, _callback);
merge(iterator beg1, iterator end1, iterator beg2, iterator end2, iterator dest)
sort(iterator beg, iterator end, _callback)
random_shuffle(iterator beg, iterator end)
reverse(iterator beg, iterator end)
拷贝|替换|集合
copy(iterator beg, iterator end, iterator dest)
replace(iterator beg, iterator end, oldvalue, newvalue)
replace_if(iterator beg, iterator end, _callback, newvalue)
swap(container c1, container c2)
accumulate(iterator beg, iterator end, value)
fill(iterator beg, iterator end, value)
set_intersection(iterator beg1, iterator end1, iterator beg2, iterator end2, iterator dest)
set_union(iterator beg1, iterator end1, iterator beg2, iterator end2, iterator dest)
set_difference(iterator beg1, iterator end1, iterator beg2, iterator end2, iterator dest)
set_symmetric_difference( one.begin(), one.end(), two.begin(), two.end() , result.begin());
算法优化举例
迭代器
简介
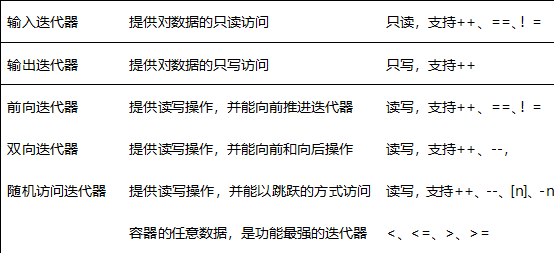
迭代器(iterator)是一种抽象的设计概念
<
STL的中心思想在于将容器(container)和算法(algorithms)分开,彼此独立设计,最后再一贴胶着剂将他们撮合在一起。从技术角度来看,容器和算法的泛型化并不困难,c++的class template和function template可分别达到目标,如果设计出两这个之间的良好的胶着剂,才是大难题。
种类
使用范围
| array | 随机访问迭代器 |
|---|---|
| vector | 随机访问迭代器 |
| deque | 随机访问迭代器 |
| list | 双向迭代器 |
| set / multiset | 双向迭代器 |
| map / multimap | 双向迭代器 |
| unordered_map / unordered_multimap | 前向迭代器 |
| unordered_set / unordered_multiset | 前向迭代器 |
| Stack/queue | 不支持 |
声明
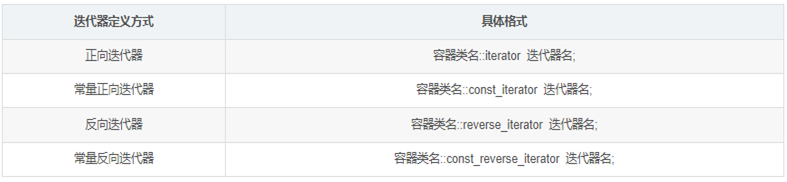
实现
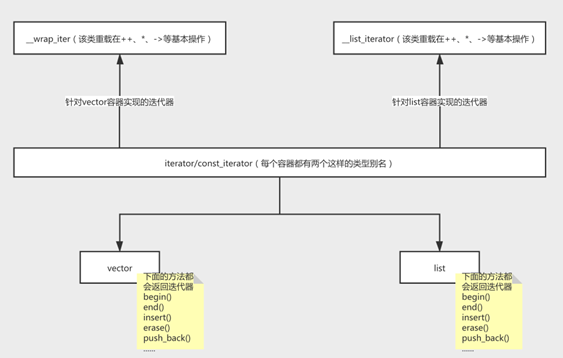
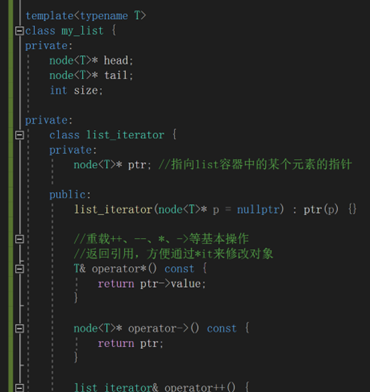
仿函数
简介
重载函数调用操作符的类,其对象常称为函数对象(function object),即它们是行为类似函数的对象,也叫仿函数(functor),最常见的用法就是重载“()”操作符,使得类对象可以像函数那样调用。
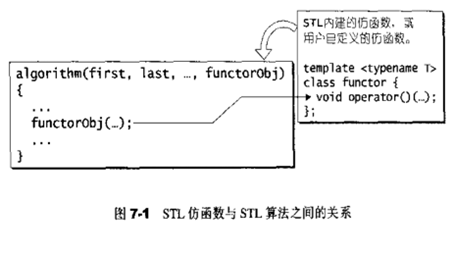
特性
一元二元
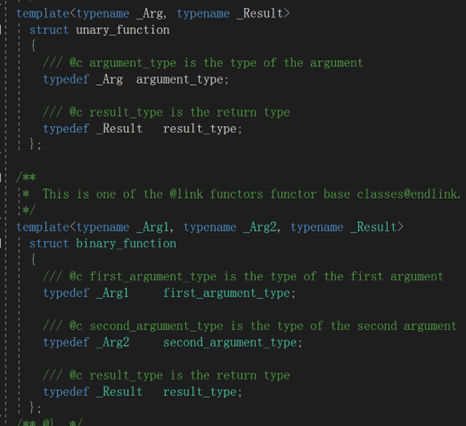
所谓的一元二元指的是我们在调用仿函数的时候需要传入几个参数,而这些仿函数统一继承于这两个类,方便后续的适配器结构。
优点
1、函数对象通常不定义构造函数和析构函数,所以在构造和析构时不会发生任何问题,避免了函数调用的运行时问题。
2、函数对象超出普通函数的概念,函数对象可以有自己的状态、属性
3、函数对象可内联编译,性能好。用函数指针几乎不可能
4、模版函数对象使函数对象具有通用性,这也是它的优势之一

适配器
简介
计算机有三宝:遍历、分治与抽象
那关我适配器什么关系呢?
我们抽象出来的模块,需要再次合在一起工作,这个时候,要是不兼容,毫无疑问需要套娃。
而适配器模式,就是我们套娃的一种姿势。
不知道大家有没有用过转接魔方,那个东西就是对于适配器模式的最好解释。
当底层的核心功能匹配,却因为一些形式上或者环境上的要求不符合的时候,可以使用这种设计模式。
就是将原来的类报上一层外壳,外壳和两边进行适配,从而复用之前的模块。
那这与我STL有什么关系呢?
咱举个例子:
class MyPrint :public binary_function<int,int,void>
{public: void operator()(int v1,int v2) const {……}}
for_each(_InIt _First, _InIt _Last, _Fn _Func)
我想在for_each的时候使用函数对象,但是函数对象虽然可以满足我的核心功能逻辑,但是需要传入参数不对等,咋办?这里就可以使用函数适配器
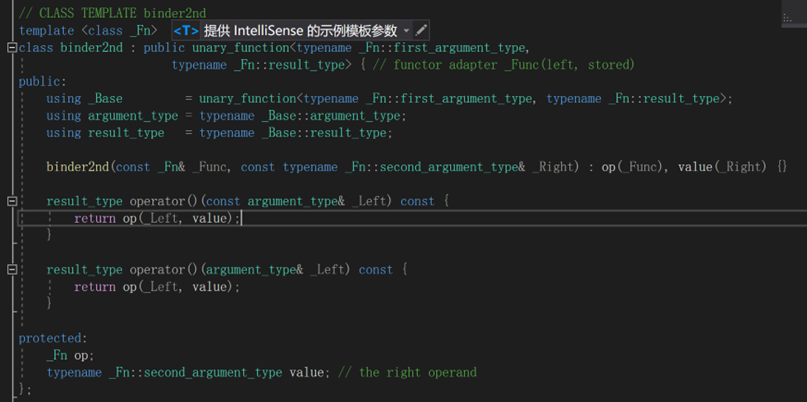
函数适配器


![image-20220613214938166]
容器适配器
和函数适配器类似的,容器适配器也是对容器的包装复用而已,我们看一看常见的容器适配器
| 表 1 STL 容器适配器及其基础容器 | ||
|---|---|---|
| 容器适配器 | 基础容器筛选条件 | 默认使用的基础容器 |
| stack | •基础容器需包含以下成员函数:empty() •size() •back() •push_back() •pop_back() 满足条件的基础容器有 vector、deque、list。 | deque |
| queue | •基础容器需包含以下成员函数:empty() •size() •front() •back() •push_back() •pop_front() 满足条件的基础容器有 deque、list。 | deque |
| priority_queue | •基础容器需包含以下成员函数:empty() •size() •front() •push_back() •pop_back() 满足条件的基础容器有vector、deque。 | vector |
迭代器适配器

空间配置器
简介
分配空间是构建对象的先行条件,构建STL容器,也离不开对空间的申请和管理。
先来看看我们所习惯的c++内存操作:
new/delete (new: 首先operator new 配置内存,然后调用构造函数构造对象;
delete:先调用析构函数析构对象,在operate delete 释放内存)
STL决定将上面的两个过程分开
内存配置操作由alloc::allocate()完成,释放由alloc::deallocate()
对象构造由::construct()完成,对象析构由destroy()完成。
在STL中,配置器定义在< memory >中,里面包含三个头文件:
<stl_construct.h>(这里定义了全局函数construct()与destroy(),负责对象的构造与析构)
<stl_alloc.h>(这里定义了一,二级配置器,彼此合作,后面解释什么是一二级配置器),
<stl_uninitialized.h>(这里面定义了一些全局函数,用来填充或复制大块内存数据
注意,以上描述是基于SGI STL的描述
一、二级空间配置器
管理空间,就会有一个绕不开的问题,就是管理效率。
假设每次申请需要1ms,申请一百个空间和申请一个空间的效率就会差一百倍。
同样如果申请了一百个小空间,意味着有一百个空间被破坏了完整性。
为了解决小型区域可能造成的碎片问题,我们设置双层级配置器。
第一级配置器,直接调用malloc()与free().第二季配置根据情况采用不同策略;当配置区过大(超过128bytes),我们就调用一级配置器,当配置区过小,为了降低负担,我们便采用memory pool 的整理方式,进而不采用第一级配置器。
第一级配置器工作函数:
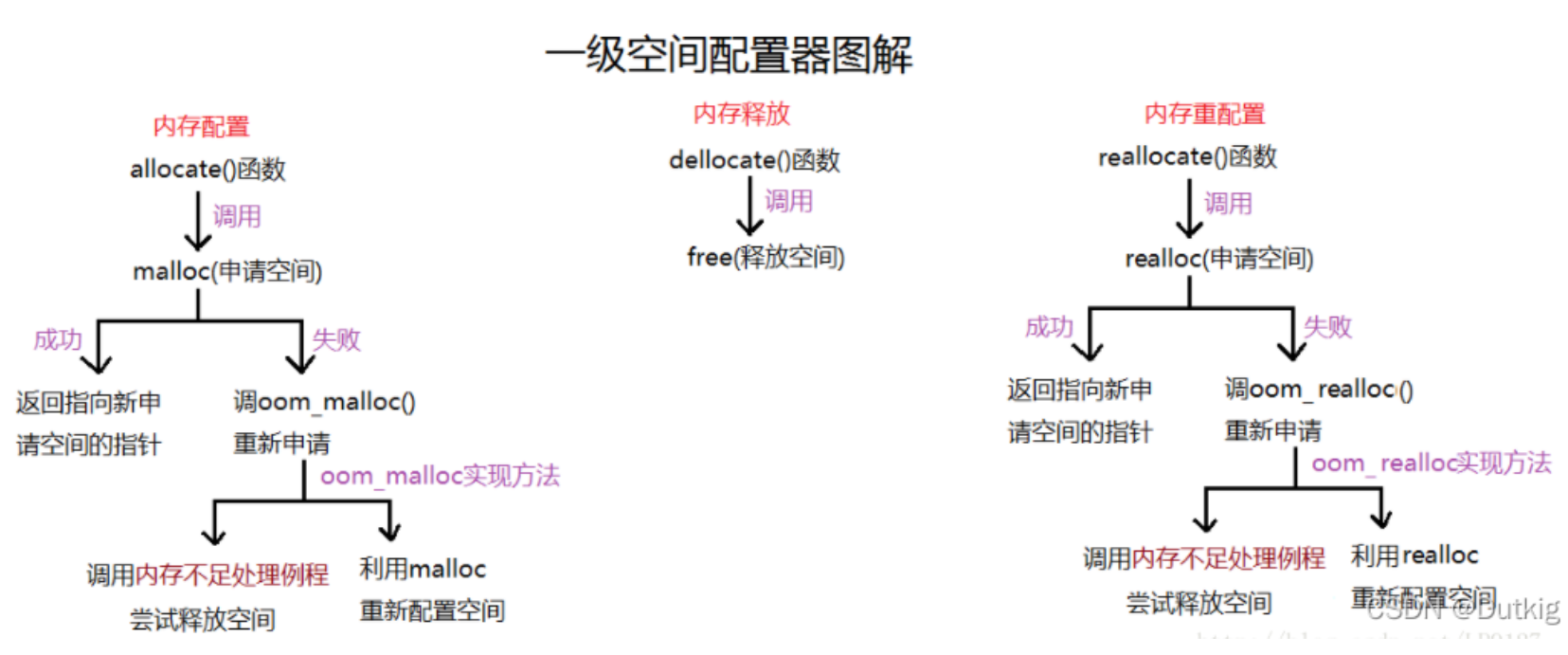
本质就是粗暴的申请内存,仅此而已,那如果说内存不够了咋办?所以,我们需要一个handle机制。
第一级配置器并不使用C的new,以 malloc(), free(), realloc() 等 C函式执行实际的内存配置、释放、重配置动作。但是它仿造了C new handler 机制。
那我们就先了解一下new handler 机制。
在C的某些旧版编译器会将new 失败的返回值置为null,但是一般是抛出std:bad_alloc异常,如果不捕捉这个异常,程序会abort。此外,new分配内存失败不仅仅是被try{}catch{}捕捉,还可以被new_handler捕捉。也就是说,你可以要求系统在内存配置需求无法被满足时,唤起一个你所指定的函式。在你唤醒的函数中,执行异常处理。【参见《Effective C》2e 条款 7】
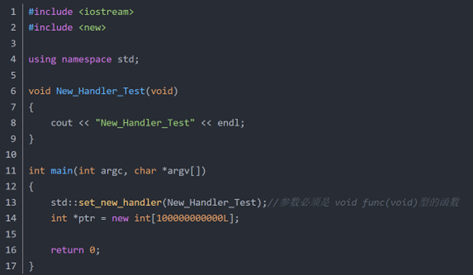
SGI 第一级配置器的 allocate() 和 realloc() 都是在呼叫 malloc()和 realloc() 不成功后,改呼叫 oom_malloc() 和oom_realloc() 。后两者都有内循环,不断呼叫「内存不足处理例程」,期望在某次呼叫之后,获得足够的内存而圆满达成任务。但如果「内存不足处理例程」并未被客端设定,oom_malloc() 和 oom_realloc() 便老实不客气地呼叫 __THROW_BAD_ALLOC ,丢出bad_alloc异常讯息,或利用 exit(1) 硬生生中止程序。

第二级配置器多了一些机制,避免太多小额区块造成内存的破碎。小额区块带来的其实不仅是内存破碎而已,配置时的额外负担(overhead)也是一大问题 。
区块愈小,额外负担所占的比例就愈大、愈显得浪费。
SGI第二级配置器的作法是,如果区块够大,超过 128 bytes,就移交第一级配置器处理。当区块小于 128 bytes,则以记忆池(memory pool)管理,此法又称为次层配置(sub-allocation):每次配置一大块内存,并维护对应之自由串行(free-list)。下次若再有相同大小的内存需求,就直接从free-lists中拨出。如果客端释还小额区块,就由配置器回收到free-lists中—是的,别忘了,配置器除了负责配置,也负责回收。为了方便管理,SGI第二级配置器会主动将任何小额区块的内存需求量上调至8的倍数(64位)(例如客端要求 30 bytes,就自动调整为 32bytes),并维护 16 个 free-lists,各自管理大小分别为 8, 16, 24, 32, 40, 48, 56, 64, 72,80, 88, 96, 104, 112, 120, 128 bytes的小额区块。
二级配置器的大概结构如下:
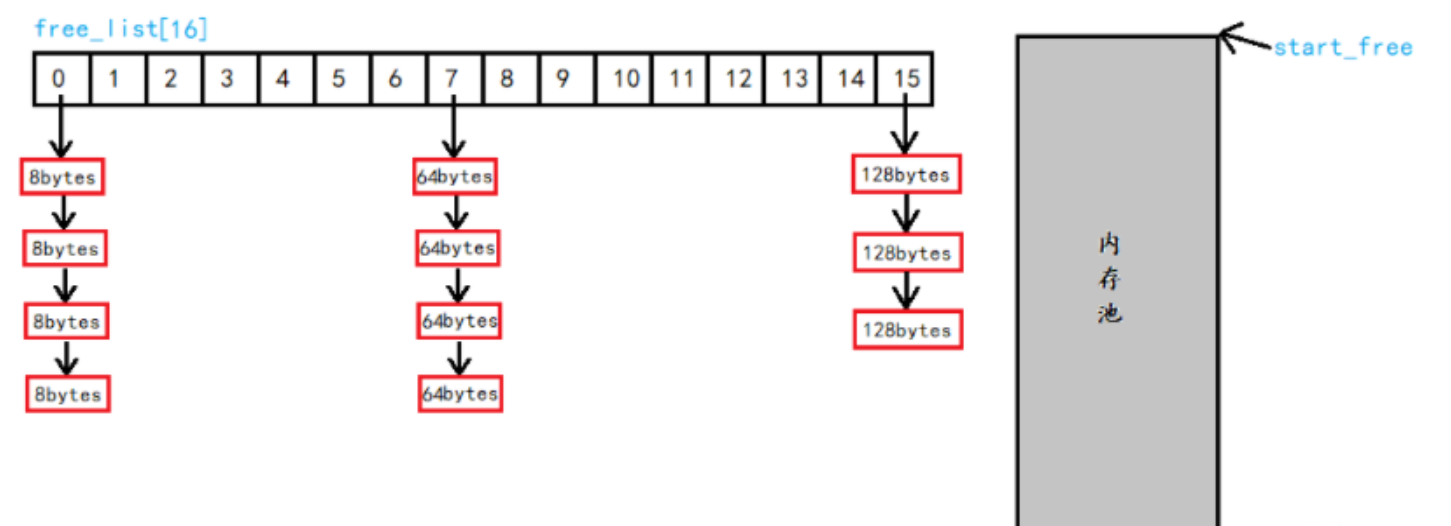
每一个节点定义如下:
union obj {
union obj * free_list_link;
char client_data[1]; /* The client sees this. */
};
Q.E.D.

